

This paper is available on arxiv under CC 4.0 license.
Authors:
(1) Jakob Vogel, M.A. Digital Humanities, Institute for Digital Humanities, Faculty of Philosophy, Georg August University of G¨ottingen.
Table of Links
- Abstract and Intro
- Diverse cross-document coreference and media bias analysis
- Annotation tool
- Annotation guidelines
- Conclusion and future work
- Acknowledgements
- Bibliographical References
Abstract
This paper presents a scheme for annotating coreference across news articles, extending beyond traditional identity relations by also considering near-identity and bridging relations. It includes a precise description of how to set up Inception, a respective annotation tool, how to annotate entities in news articles, connect them with diverse coreferential relations, and link them across documents to Wikidata’s global knowledge graph. This multi-layered annotation approach is discussed in the context of the problem of media bias. Our main contribution lies in providing a methodology for creating a diverse cross-document coreference corpus which can be applied to the analysis of media bias by word-choice and labelling.
Keywords: coreference resolution, diverse coreference annotation, entity annotation, entity linking, media bias analysis, natural language processing
1. Introduction
Coreference is the phenomenon of several expressions in a text all referring to the same person, object, or other entity or event as their referent. Thus, in a narrow sense, analyzing a document with regards to coreference means detecting relations of identity between phrases. The following example (1) illustrates such an identity relation, where coreferential expressions are printed in italics:
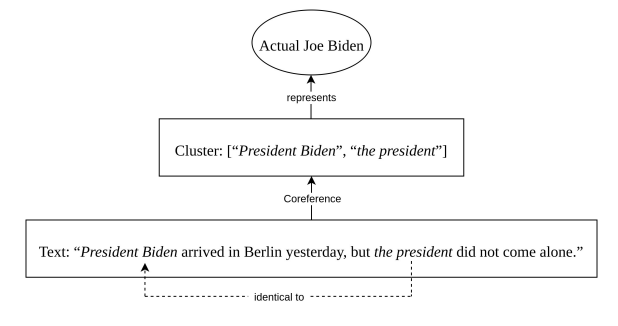
(1) “Joe Biden arrived in Berlin yesterday, but the president did not come alone.”
In (1), the noun phrase “Joe Biden” introduces a new entity while “the president” relates back to that introducing phrase. Within this relation, the introducing phrase “Joe Biden” is called the antecedent while the back-relating phrase “the president” is called an anaphor. Both expressions are coreferential in the way that they refer to the same non-textual entity, namely to the actual ‘realworld’ Joe Biden or at least to a corresponding mental concept. We can think of an antecedent and its anaphora as forming a cluster of mentions that as a whole represents its extra-textual referent within a textual document, as shown in Figure 1.
As a task of natural language processing (NLP), coreference resolution has become quite efficient in detecting identity relations between phrases. However, reflecting on how we use language to refer to something, we are forced to realize that coreference in a broader sense is actually far more complex. We can address an entity or event by using a variety of expressions that are in fact not strictly identical to each other. Consider the following examples:
(2) “President Biden was clearly not satisfied with today’s outcome. As the White House stated this afternoon, efforts will be made to . . . ”
(3) “Even if the young Erdogan used to be pro-Western, Turkey’s president nowadays often acts against Western interests.”
(4) “The AfD is circulating a photo of Angela Merkel with a Hijab, although Merkel never wore Muslim clothes.”
In these given examples, the highlighted mentions mean ‘almost’ the same, but not completely. In (2), we are aware by world-knowledge that ”the White House” is often used as a substitute expression for the current US president, although the former is a place which in strict terms cannot be identical to the president, who is a person. In (3), on the other hand, both mentions refer to the ’real-world’ person Erdogan, but at different time steps. Finally, in (4), a mention representing the person Merkel is juxtaposed with a mention representing a picture of Merkel. While these two mentions could refer to separate entities, the juxtaposition indicates a connection between both where the attributes of the first mention do influence the perception of the second mention. Hence, we would miss essential semantic connections if we chose not to mark them as coreferential. Having said that, the simple classification of two mentions into coreferential (identical) or noncoreferential (non-identical) does not seem to suffice the complexity of common text data. Instead, we need to allow for diverse coreference clusters that include finer-grained relations lying between identity and non-identity. We need to allow for near-identity relations to mark two mentions that are partially, but not totally, identical (Recasens et al., 2010).
In news coverage, identity and near-identity references are extensively used to report on persons, organizations, and other entities of public interest. It is our goal to build up a corpus that contains annotated examples of such diverse forms of coreference. While diverse coreference occurs in all sorts of news media, we focus on digital print media, only. Furthermore, although in practice both entities and events can act as referent, we ignore references to events for now, as their annotation would go beyond the limits of our present scheme.[1]
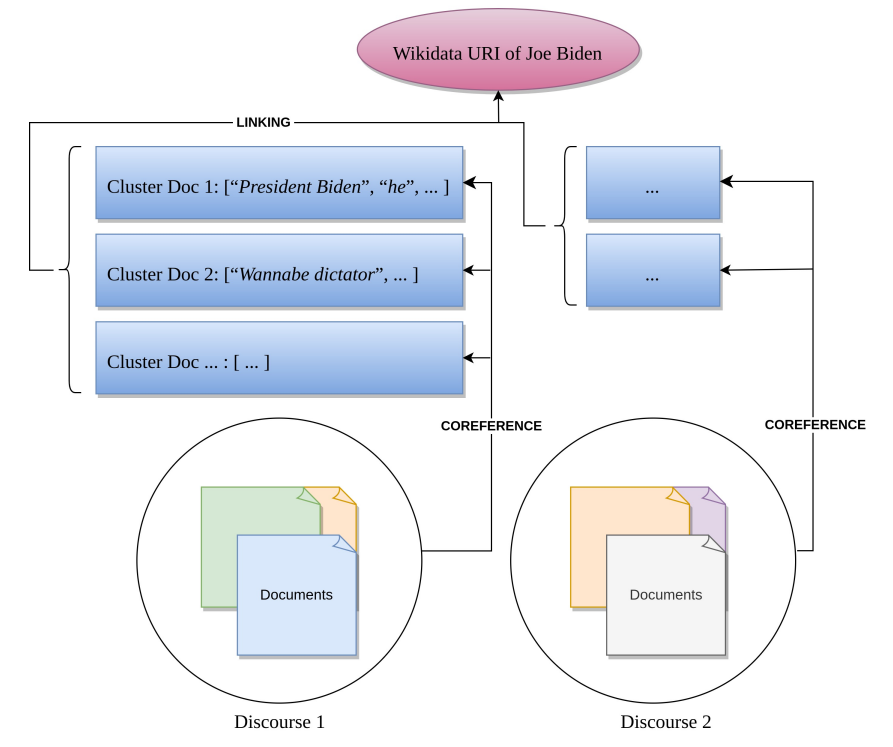
The ordinary business of journalism is to write about current political affairs and other happenings of public interest. These happenings are normally reported by several newspapers at the same time. All of these news articles are considered documents that contain references to the same entities and together form a discourse about them. To include the whole picture of such intradiscursive references, we want our corpus to link document-level clusters with corresponding clusters of other documents of the same discourse. Hence, our corpus is to depict cross-document coreference data. On a discourse level, corresponding clusters form discourse entities that themselves can be linked to their non-textual referents by some knowledge graph identifier. For this project, we use Wikidata’s Uniform Resource Identifiers (URIs) for entity linking. By doing so, world knowledge is included into the data. This allows for drawing connections even between different discourse entities that refer to a common referent, yet at a different time step or rather in the context of a different happening. Figure 2 illustrates the multiple layers of this annotation model.
In building a corpus for diverse cross-document coreference in news articles, we hope to provide a valuable resource for the evaluation of automated coreference resolution tasks. The contribution of this paper mainly lies in providing an answer to the question of how to create such a corpus. How can diverse coreference relations be annotated in a cross-document setup? We believe our scheme as we present it here tackles this problem efficiently, extensively, and unambiguously.
Additionally, we would like to use the data resulting from our own annotations for further research in the area of media bias. Even if it plays no direct part in the outlined scheme, a lot of our choices how to annotate references were made because of this requirement to make the data usable for later media bias analysis. Eventually, we hope to contribute to the wider research question of how to identify media bias by word choice and labelling based on the usage of diverse coreference relations in news articles.
The following section 2 will further elaborate on this connection between diverse coreference and the problem of media bias analysis. Despite its only subtle impact on our practical annotation instructions, that section means to highlight the theoretical background and motivation behind our project. The sections thereafter will then deal with the actual annotation process. Section 3 will guide coders through the setup and controls of Inception, our selected annotation software. Finally, section 4 will define annotation instructions in three passes while also outlining our typology of diverse coreference.
The data we use for our own annotations consists of the text bodies of articles that report on the same happenings. All articles are in English and were published by one of the following US-American newspapers: HuffPost (categorized as ”Left” by AllSides (2023) or ”Skews Left” by Ad Fontes Media (2023), abbreviated in our data as ”LL”), The New York Times (categorized as ”Lean Left” by AllSides or ”Skews Left” by Ad Fontes Media, abbreviated as ”L”), USA Today (categorized as ”Lean Left” or ”Middle or Balanced Bias”, abbreviated as ”M”), Fox News (categorized as ”Right” or ”Skews Right”, abbreviated as ”R”), Breitbart News Network (categoized as ”Right” or ”Strong Right”, abbreviated as ”RR”).[2]
[1] Though at a later point, this scheme could be extended to also include the annotation of events (Linguistic Data Consortium, 2005; O’Gorman et al., 2016).
[2] Looking at the political orientation of these newspapers, the data is unbalanced with an underrepresentation of politically centered media. However, at the current state of this project, the imbalance is unlikely to influence our analysis which does not yet target political orientation or media bias itself. Therefore, we will ignore this issue for now.