
Table of Links
A. Mathematical Formulation of WMLE
C Qualitative Bias Analysis Framework and Example of Bias Amplification Across Generations
D Distribution of Text Quality Index Across Generations
E Average Perplexity Across Generations
F Example of Quality Deterioration Across Generations
4 Experiment Design
In this section, we present and explain in detail the experiments designed to investigate the bias amplification of LLMs (see results in Section 5). Specifically, we analyze the sequential and synthetic fine-tuning of GPT-2. While similar experiments could be conducted with larger models such as GPT-4 or Claude in non-fine-tuning contexts, doing so would likely incur significant environmental costs. The focus of this study is on political bias within the US political spectrum, particularly in the context of sentence continuation tasks. This is important because LLMs are increasingly becoming a source of information for global news consumption (Maslej et al., 2024; Peña-Fernández et al., 2023; Porlezza and Ferri, 2022), and traditional news outlets, such as the Associated Press, are beginning to incorporate LLMs to automate content generation from structured data (The Associated Press, 2024).
4.1 Experiment Dataset Preparation
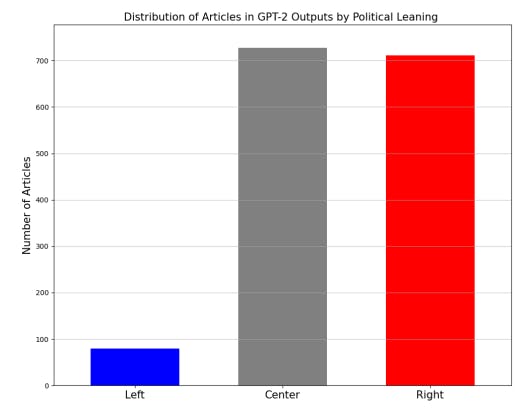
We randomly selected 1,518 articles from the Webis-Bias-Flipper-18 dataset (Chen et al., 2018), which contains political articles from a range of U.S. media outlets published between 2012 and 2018, along with bias ratings assigned at the time for each media source. These ratings were provided by Allsides and were determined through a multistage process involving both bipartisan experts and members of the general public (AllSides, 2024a). Based on the bias ratings, the random selection was stratified to ensure that the 1,518 articles were evenly divided into three groups of 506 articles each, representing left-leaning, right-leaning, and center-leaning media.
4.2 Fine-tuning and Synthetic Data Generation
Inspired by (Shumailov et al., 2024; Dohmatob et al., 2024b), each training cycle begins with GPT2 fine-tuned on the dataset of human-written political articles. The fine-tuned GPT-2 is then used to generate the first set of synthetic data, which is subsequently employed to further fine-tune the model, producing model generation 1. This iterative process continues until generation 10 is reached. For details on the fine-tuning setup, refer to Appendix B.
Synthetic datasets are created as follows: we begin by tokenizing each original article and dividing it into 64-token blocks. For each block, the model generates a continuation by predicting the next 64 tokens based on the tokenized input. We employ three generation methods: (1) deterministic, (2) beam search (num_beams = 10) (Holtzman et al., 2020; Taori and Hashimoto, 2022), (3) Nucleus sampling (top_p = 0.9) (Graves, 2012; Taori and Hashimoto, 2022). Once all blocks are processed, the synthetic tokens are decoded back into text. This procedure is applied to all articles, resulting in a synthetic dataset of the same size as the original.
4.3 Political Bias Metric
We develop a metric model to classify the political leaning of synthetic outputs generated by large language models. The classifier assigns labels corresponding to left, center, and right-leaning, trained on data from AllSides (AllSides, 2024a), a source that assigns bias ratings to each media outlet. The methodology for the classifier is as follows:
Dataset and Preprocessing. We use a dataset consisting of political articles with labeled bias categories for the source media: left, center, and right. We concatenate the article titles with their body text to form the input. To address class imbalance, we resample the center-leaning articles, balancing the dataset with respect to each category. The dataset is then split into training (70%), validation (15%), and test (15%) subsets, stratified by bias label. Moreover, we conduct a human review of the test subsets to eliminate any identifiable information about media sources or writers.

Training Procedure. Tokenization is performed using each model’s respective tokenizer with a maximum sequence length of 512 tokens. To mitigate overfitting, weight decay of 0.01 is applied during training. The model checkpoints are saved after each epoch, and the best model is selected based on macro F1 score evaluated on the validation set. We use a weighted random sampler during training to ensure balanced class representation.
Evaluation Metrics. We evaluate the models using the macro F1 score to account for the multiclass nature of the task, ensuring that performance is balanced across all bias categories. The final evaluation is conducted on the held-out test set. Additionally, we report the loss, runtime, and sample processing rates for completeness.
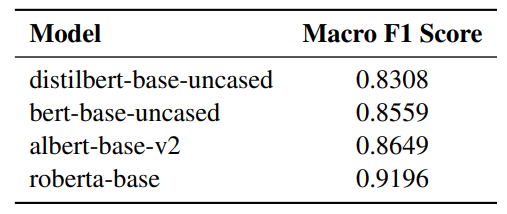
Results. After conducting a grid search across several models, we find that the roberta-base model achieves the best performance with an evaluation loss of 0.4035 and a macro F1 score of 0.9196 on the test set (see Table 1). Thus, roberta-base model is selected as the benchmark for political bias detection in subsequent experiments.
4.4 Generation Quality Metric
We introduced a metric for evaluating generation quality, specifically addressing the issue of repetitive content in later model iterations, which can skew traditional perplexity metrics. This metric is based on the Gibberish Detector (Jindal, 2021), which identifies incoherent or nonsensical text. The detector classifies text into four categories: (1) Noise, where individual words hold no meaning; (2) Word Salad, where phrases are incoherent; (3) Mild Gibberish, where grammatical or syntactical errors distort meaning; and (4) Clean, representing coherent, meaningful sentences. To evaluate generation quality, we assign the Gibberish score to each sentence: 3 for Clean, 2 for Mild Gibberish, 1 for Word Salad, and 0 for Noise. An average score is calculated for each article, resulting in the text quality index. It focuses on the coherence and meaning of the generated text and outperforms perplexity in accurately reflecting actual generation quality, as demonstrated in Section 5.2.
Authors:
(1) Ze Wang, Holistic AI and University College London;
(2) Zekun Wu, Holistic AI and University College London;
(3) Jeremy Zhang, Emory University;
(4) Navya Jain, University College London;
(5) Xin Guan, Holistic AI;
(6) Adriano Koshiyama.
This paper is available on arxiv under CC BY-NC-SA 4.0 license.